by Ross Goodwin
A Watch
IPFS

3 August 2022•TEZOS•IPFS
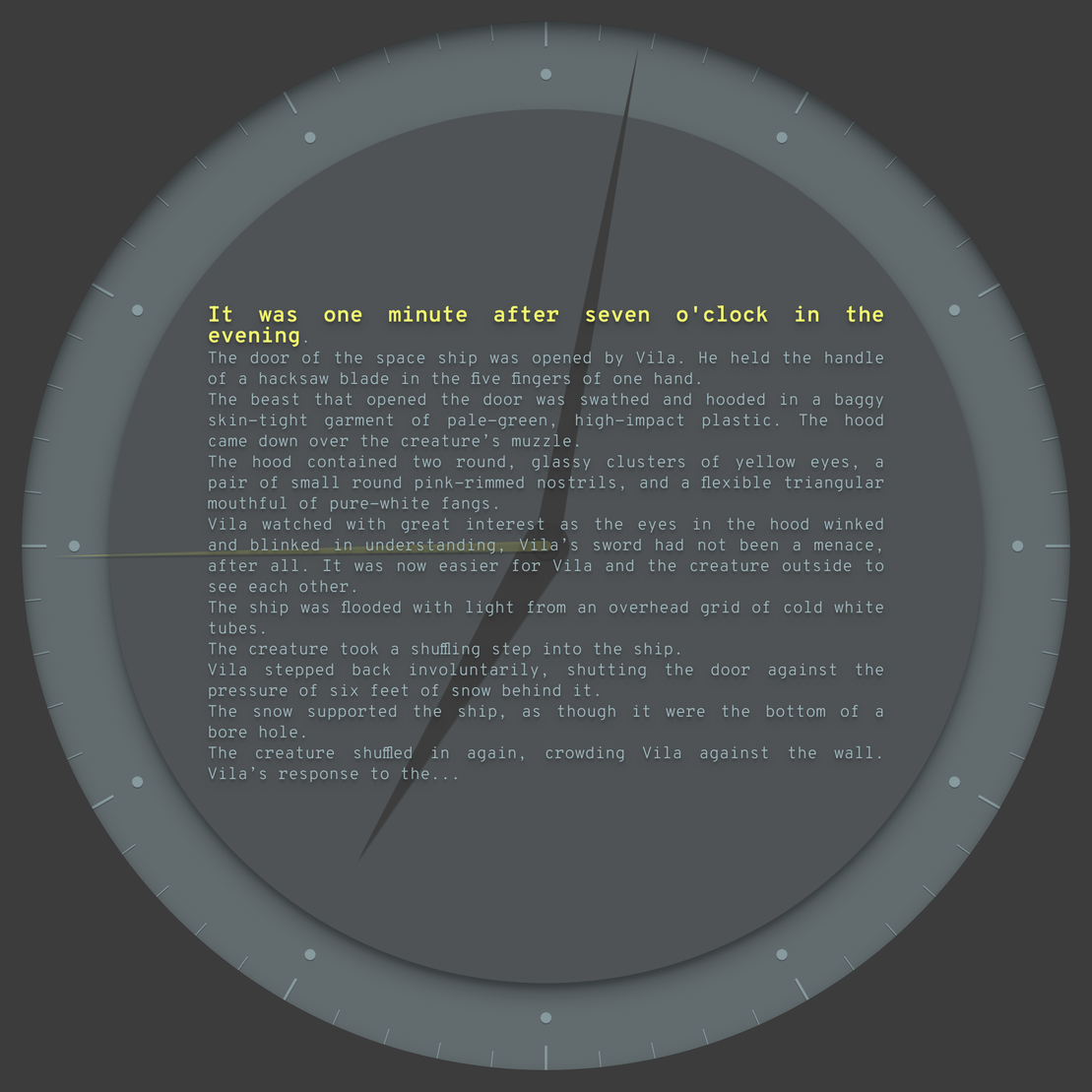
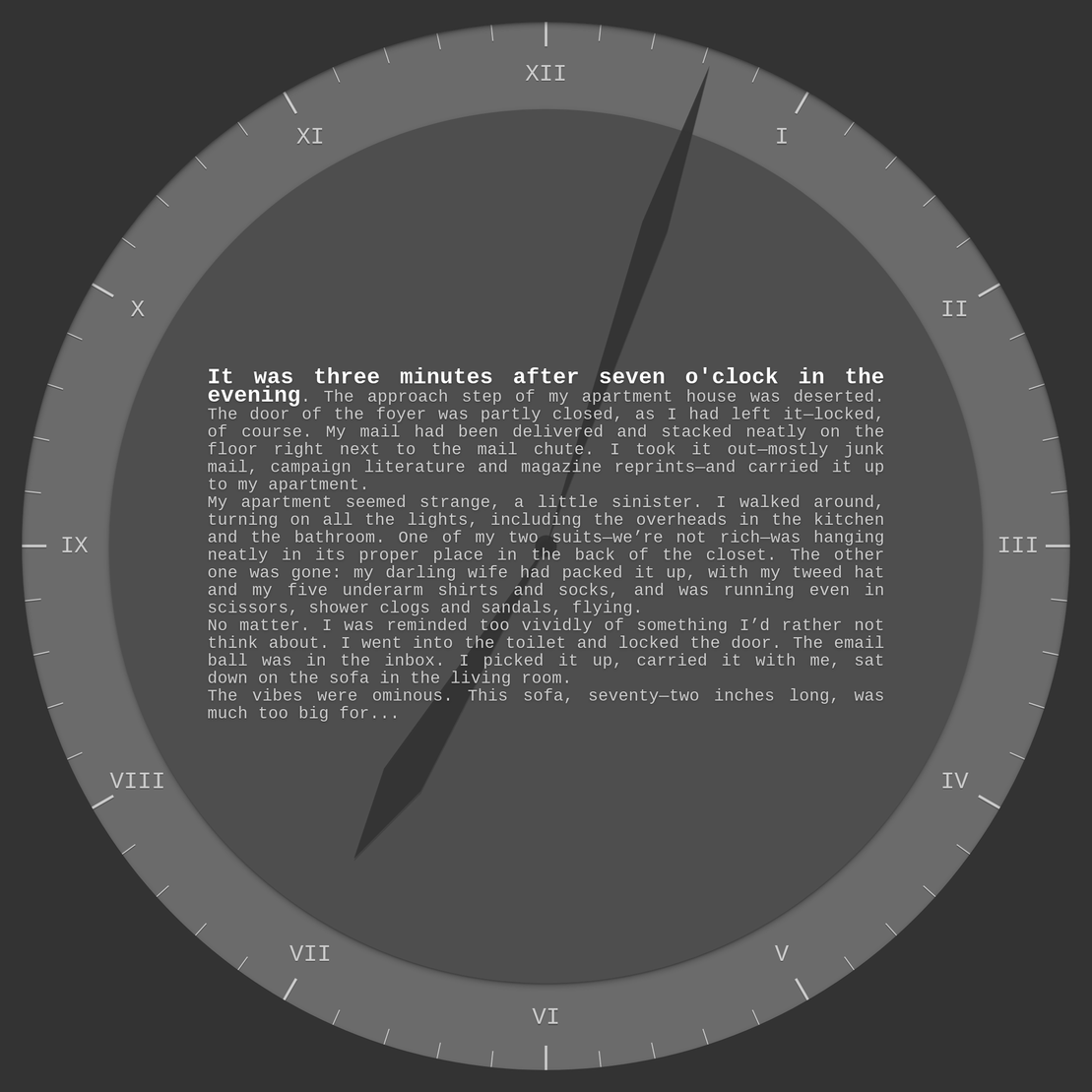
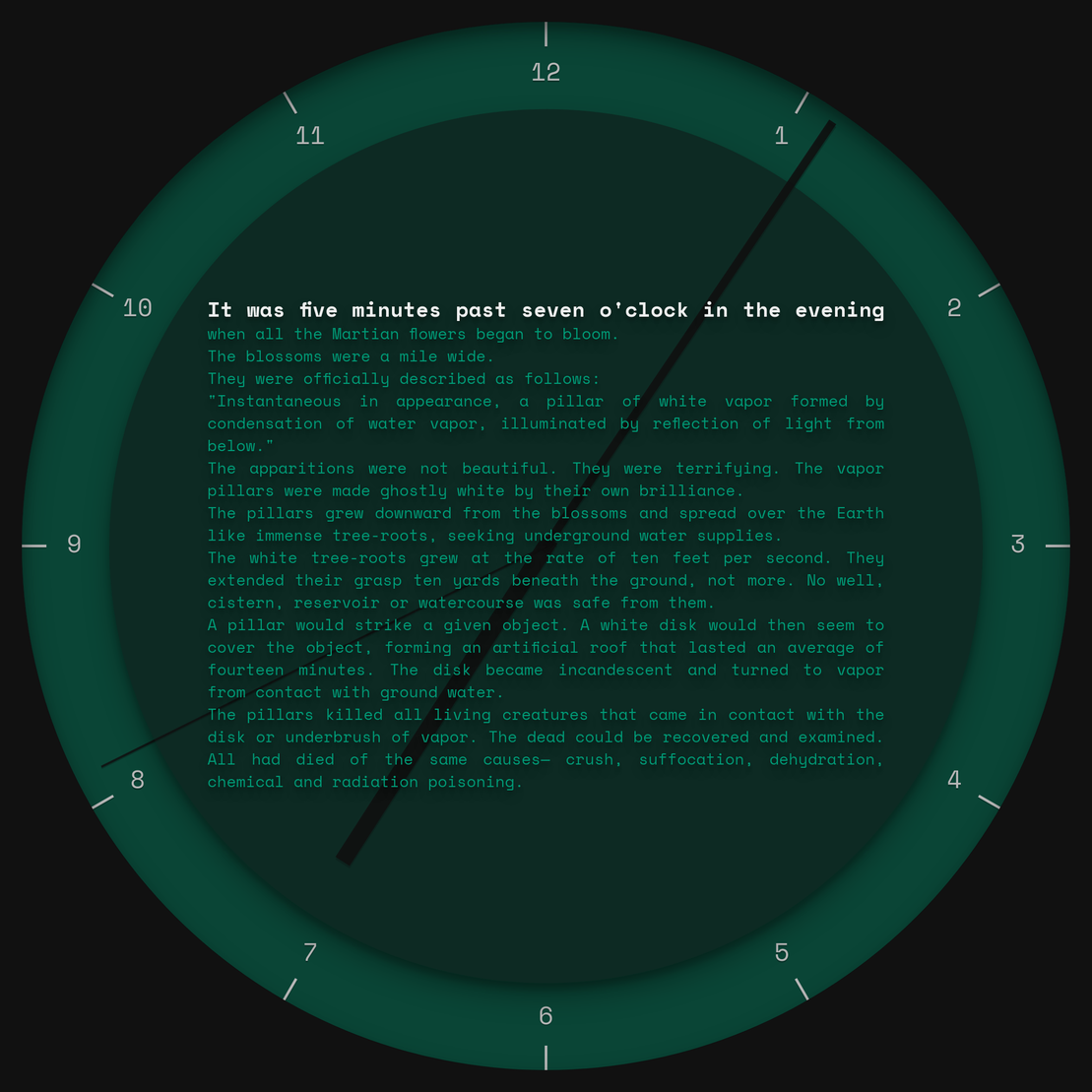
Another adventure in narrated horology: this work features entirely new texts, authored by AI that I trained on a set of novels. Each minute is an AI prose output, a fragment of a novel that doesn't exist, generated from the time itself.
The form factor is ideal for smaller window sizes and displays, although it will scale to any size. With the right device, you could probably wear it on your wrist.
Nearly 5,000 unique text templates are included, many of which feature variable character names, for which I sourced approximately 1.8 million possible first names and 150,000 possible surnames from U.S. Census data: https://github.com/rossgoodwin/american-names
I wanted to provide just enough text for each minute so that you could read the whole excerpt before the minute ends, though you might need to read briskly. None of the passages have been edited manually, and some remain quite glitchy, as intended. You may recognize a few motifs or proper names here and there, depending on the books you're familiar with, but each passage remains wholly original otherwise.
Each edition features either a linear or nonlinear text sequence:
Nonlinear editions will all show one of two possible template texts for each minute, and will read like fragments from multiple (strange and glitchy) novels. Nonlinear sequences feature independently generated texts, with variable character names unique to each minute of each edition.
Linear editions will all show the same template text for each minute, and will read like (strange and glitchy) 24-hour novels. For linear sequences, I utilized a generative prompting technique in which each minute's text is generated partially from the text of the minute before it. Variable character names for linear sequences are unique to each edition and repeat throughout the day.
Aesthetic possibilities for each edition include 16 color palettes, 8 fonts, 7 depths, 5 types of numerals, and 3 types of hands. Some editions have color-accented second hands and minute marks, while others appear more static and minimalist, without any numerals or second hand at all.
This token relies on p5.js for the clockwork, vanilla JS for the text.
Double click to toggle fullscreen.
Push `d` to download current minute's text as a .txt file.
Some copyrighted materials were used (under U.S. copyright law's fair use doctrine) to train the language model that wrote each passage, but training materials only serve as an intermediary for the final output presented here. In simpler terms, no copyrighted work is present in this generative token, but some was used to make it (under fair use).
That said, with OpenAI's GPT-3 used as the base model, my (finetune) training corpus included the following books:
- Heart of Darkness by Joseph Conrad
- Surfacing by Margaret Atwood
- To the Lighthouse by Virginia Woolf
- The Sun Also Rises by Ernest Hemingway
- On the Road by Jack Kerouac
- The Crying of Lot 49 by Thomas Pynchon
- The Sirens of Titan by Kurt Vonnegut
- Fear and Loathing in Las Vegas by Hunter S. Thompson
- The Broom of the System by David Foster Wallace
N.B. My opinions about these books, and these authors, have changed over the years. I wanted to achieve a cohesive and specific voice by combining works I thought would complement one another in tone and themes, which required me to use books I'd actually read at some point. I'm only human, and the number of books I've read in my life remains a grossly mortal figure, unlike some of the language models I've worked with over the years. I know I have unknown biases, just as large gaps in my library remain, and so I welcome any suggestions for future training material sets from the community that might improve the diversity of voices represented in works like this one.
ABOUT THE CREATOR
Ross Goodwin is an artist, creative technologist, and former White House ghostwriter. He employs machine learning, natural language processing, and other computational tools to realize new forms and interfaces for written language.
rossgoodwin.com
The form factor is ideal for smaller window sizes and displays, although it will scale to any size. With the right device, you could probably wear it on your wrist.
Nearly 5,000 unique text templates are included, many of which feature variable character names, for which I sourced approximately 1.8 million possible first names and 150,000 possible surnames from U.S. Census data: https://github.com/rossgoodwin/american-names
I wanted to provide just enough text for each minute so that you could read the whole excerpt before the minute ends, though you might need to read briskly. None of the passages have been edited manually, and some remain quite glitchy, as intended. You may recognize a few motifs or proper names here and there, depending on the books you're familiar with, but each passage remains wholly original otherwise.
Each edition features either a linear or nonlinear text sequence:
Nonlinear editions will all show one of two possible template texts for each minute, and will read like fragments from multiple (strange and glitchy) novels. Nonlinear sequences feature independently generated texts, with variable character names unique to each minute of each edition.
Linear editions will all show the same template text for each minute, and will read like (strange and glitchy) 24-hour novels. For linear sequences, I utilized a generative prompting technique in which each minute's text is generated partially from the text of the minute before it. Variable character names for linear sequences are unique to each edition and repeat throughout the day.
Aesthetic possibilities for each edition include 16 color palettes, 8 fonts, 7 depths, 5 types of numerals, and 3 types of hands. Some editions have color-accented second hands and minute marks, while others appear more static and minimalist, without any numerals or second hand at all.
This token relies on p5.js for the clockwork, vanilla JS for the text.
Double click to toggle fullscreen.
Push `d` to download current minute's text as a .txt file.
Some copyrighted materials were used (under U.S. copyright law's fair use doctrine) to train the language model that wrote each passage, but training materials only serve as an intermediary for the final output presented here. In simpler terms, no copyrighted work is present in this generative token, but some was used to make it (under fair use).
That said, with OpenAI's GPT-3 used as the base model, my (finetune) training corpus included the following books:
- Heart of Darkness by Joseph Conrad
- Surfacing by Margaret Atwood
- To the Lighthouse by Virginia Woolf
- The Sun Also Rises by Ernest Hemingway
- On the Road by Jack Kerouac
- The Crying of Lot 49 by Thomas Pynchon
- The Sirens of Titan by Kurt Vonnegut
- Fear and Loathing in Las Vegas by Hunter S. Thompson
- The Broom of the System by David Foster Wallace
N.B. My opinions about these books, and these authors, have changed over the years. I wanted to achieve a cohesive and specific voice by combining works I thought would complement one another in tone and themes, which required me to use books I'd actually read at some point. I'm only human, and the number of books I've read in my life remains a grossly mortal figure, unlike some of the language models I've worked with over the years. I know I have unknown biases, just as large gaps in my library remain, and so I welcome any suggestions for future training material sets from the community that might improve the diversity of voices represented in works like this one.
ABOUT THE CREATOR
Ross Goodwin is an artist, creative technologist, and former White House ghostwriter. He employs machine learning, natural language processing, and other computational tools to realize new forms and interfaces for written language.
rossgoodwin.com
256 EDITIONS
•0 RESERVES
minted
256 / 256
dutch auction
4 TEZ
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH
Lorem ipsum project longer longer
0.00001 ETH